TP1 - Busca no espaço de estados
Introdução
Neste projeto, você irá implementar os principais algoritmos de busca para resolver o problema do caminho mais curto em mapas com estrutura de grade. Para isso, você utilizará uma página web acessada por meio de um servidor web local (que será executado em seu próprio computador). A partir desta página, será possível carregar mapas pré-existentes e criar novos. Além disso, você terá a capacidade de enviar os mapas para o servidor executar buscas com os algoritmos e heurísticas selecionados. O objetivo principal deste projeto é praticar a implementação de algoritmos de busca e compreender a dinâmica de exploração do espaço de estados de cada um deles. Portanto, além de implementar os algoritmos, será necessário redigir um pequeno relatório analisando os resultados obtidos de forma objetiva.
Código-base
Executar servidor
Clique aqui para baixar o código-base, que inclui o cliente em JavaScript para desenhar e carregar os mapas, bem como o servidor em Python para implementar e executar os algoritmos de busca. Para executar o servidor, você precisará instalar as dependências do projeto e iniciar o servidor com os seguintes comandos:
pip install -r requirements.txt # Instalar dependencias
python3 server.py -port 5001 # Executar o servidor
Assim que o servidor iniciar, você pode abrir o seguinte endereço em qualquer navegador: http://localhost:5001.
Estados
Todo o seu trabalho será realizado no arquivo search.py. Abra esse arquivo e se familiarize com as funções definidas. Nesta implementação, os estados são representados por tuplas (x,y) com as coordenadas das células do mapa (grid). Além disso, cada estado tem um valor 1 <= v <= 9 associado, que será utilizado para calcular o custo das ações de movimentação no mapa. Segue um exemplo de mapa:
XXXXXXXXXXXXXXXX
XS1111111111111X
X11111111111111X
X11111111111111X
X11111111111111X
X11111111111111X
X1111111111111GX
XXXXXXXXXXXXXXXX
Os caracteres X representam paredes, S = (1,1) é o estado inicial e G = (13,6) é o estado final. Todos os outros caracteres numéricos representam espaços vazios. Neste exemplo, existem apenas espaços vazios com valor v = 1. Note que S e G também são espaços vazios (onde pode ocorrer movimento) e seus estados, por definição do problema, têm valor v = 1.
O ponto de entrada de qualquer algoritmo de busca é a função plan(map, algorithm, heuristic), que já está implementada. Ela realiza o parser do mapa, transformando-o de uma matriz de caracteres em um dicionário level. Esse dicionário contém um conjunto walls, um dicionário spaces, e duas tuplas start e goal com os estados inicial e final, respectivamente. Em seguida, a função executa um algoritmo de busca para encontrar um caminho entre start e goal. O algoritmo executado dependerá do parâmetro algorithm, que por padrão é definido como a busca em largura "bfs". Para algoritmos de busca informada, a função utiliza o parâmetro heuristic para definir a função heurística utilizada durante a busca.
Tarefas
1. Modelo de transição de estados
1.1 Função de custo
Sua primeira tarefa é implementar a função de custo cost_function(state1, state2, cost1, cost2) entre dois estados state1 e state2. O custo das ações entre estados deve ser calculado pela fórmula cost = dist(state1, state2) * (cost1 + cost2)/2, onde dist é a distância euclidiana entre state1 e state2. O exemplo abaixo ilustra essa fórmula:
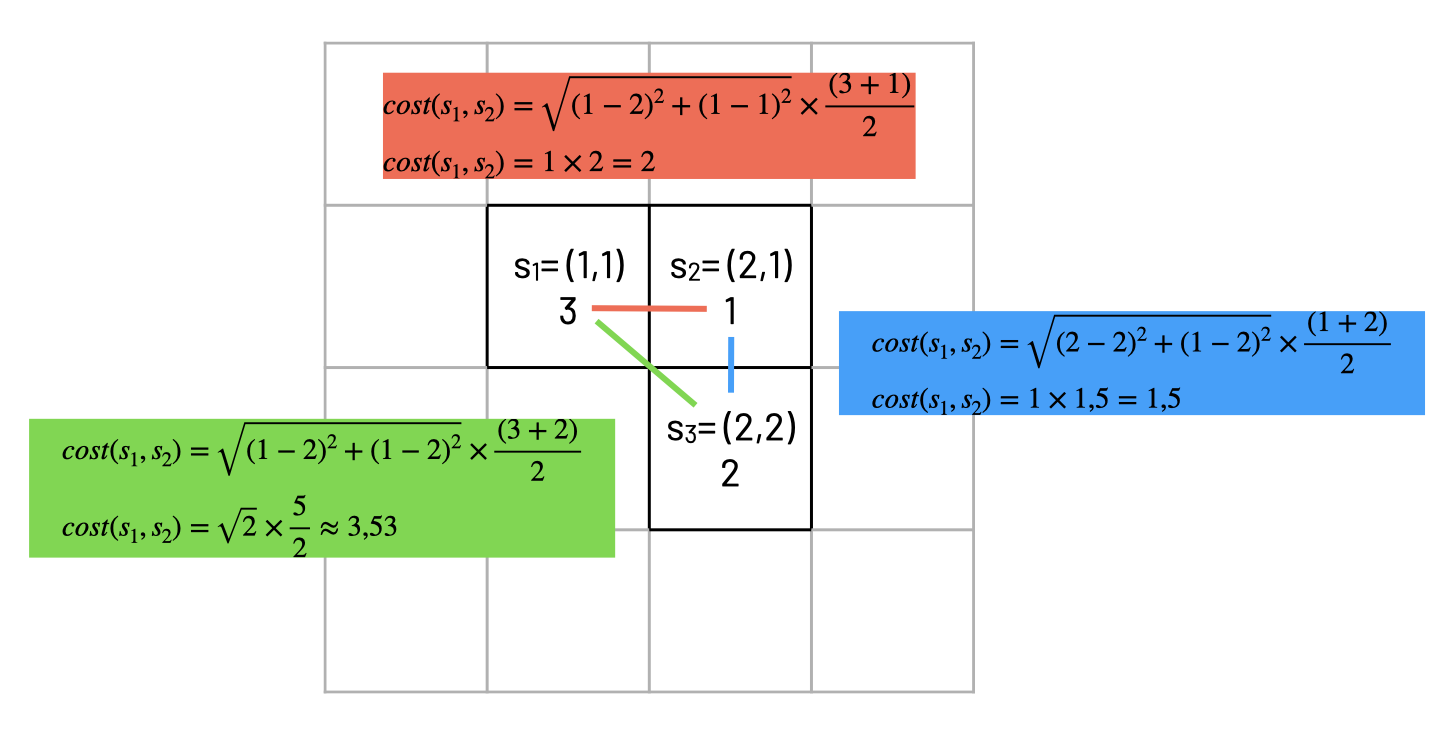
1.2 Função de transição
Em seguida, você irá implementar a função de transição de estados transition_model(level, state1), que dado um mapa representado pelo dicionário level ({walls, spaces, start, goal}) e um estado state1, retorna os próximos estados permitidos a partir de state1 e seus respectivos custos. Sua implementação deve permitir movimentos horizontais, verticais e diagonais. O custo das ações entre o estado state1 e seus vizinhos deve ser calculado com a função cost_function implementada na etapa anterior. Antes de prosseguir para a próxima etapa, teste as duas funções que você implementou verificando os vizinhos e seus custos para estados nos mapas dados de exemplo.
2. Busca não-informada
Após concluir a etapa anterior, você pode dar início à implementação dos algoritmos de busca.
2.1 Busca em largura
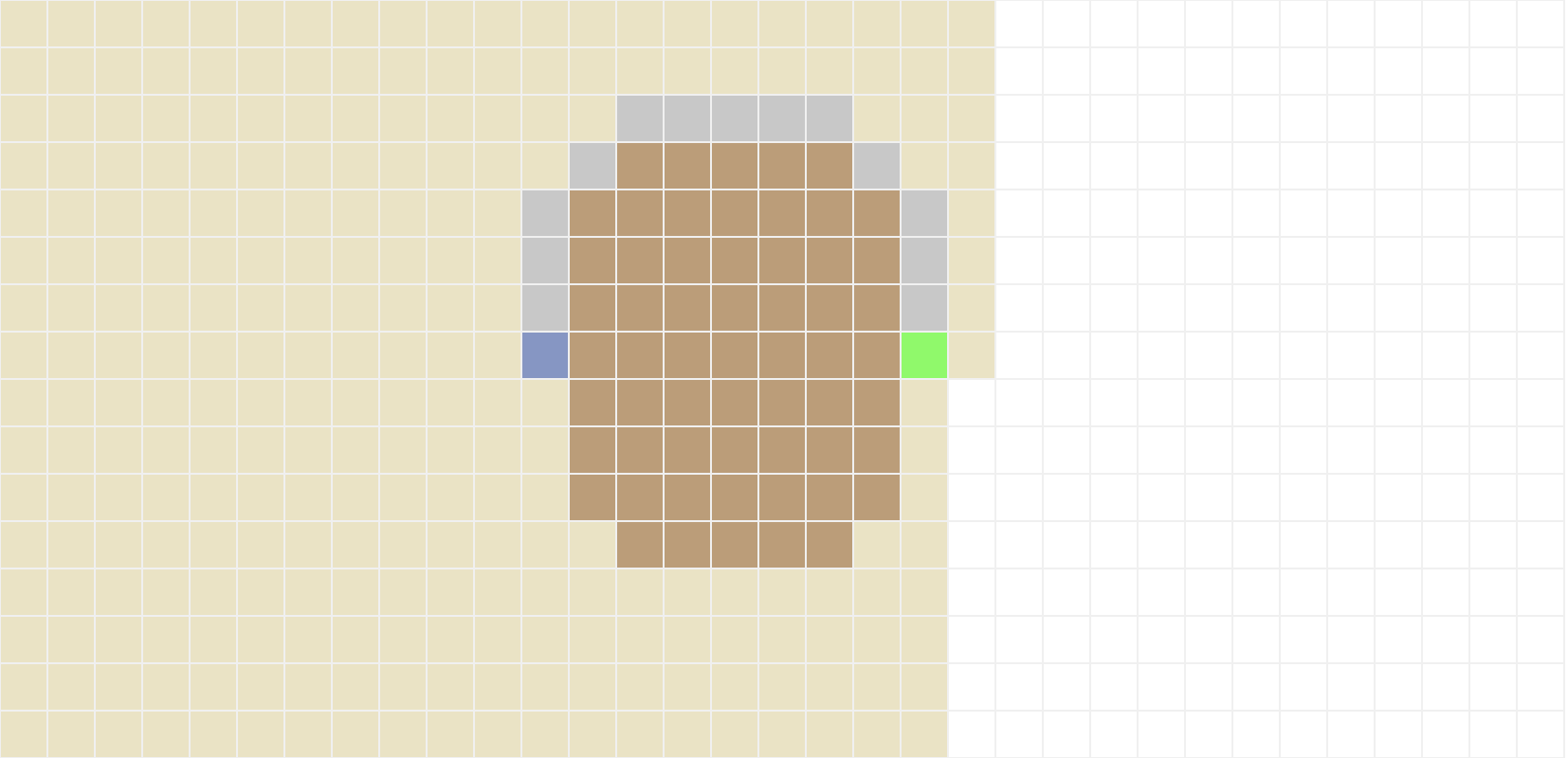
Para implementar a busca em largura, você deve criar a função bfs(s, g, level, adj), que recebe como parâmetros o estado inicial s, o estado final g, o mapa representado pelo dicionário level e a função de transição adj. A função bfs deve retornar uma lista path com o caminho entre s e g encontrado pela busca em largura e um dicionário visited contendo todos os estados visitados durante o processo. Se o problema não tiver solução, o caminho retornado deve ser uma lista vazia, mas o dicionário visited ainda conterá todos os nós visitados até a parada do algoritmo. O resultado esperado para os mapas 1, 3 e 7 são os seguintes:


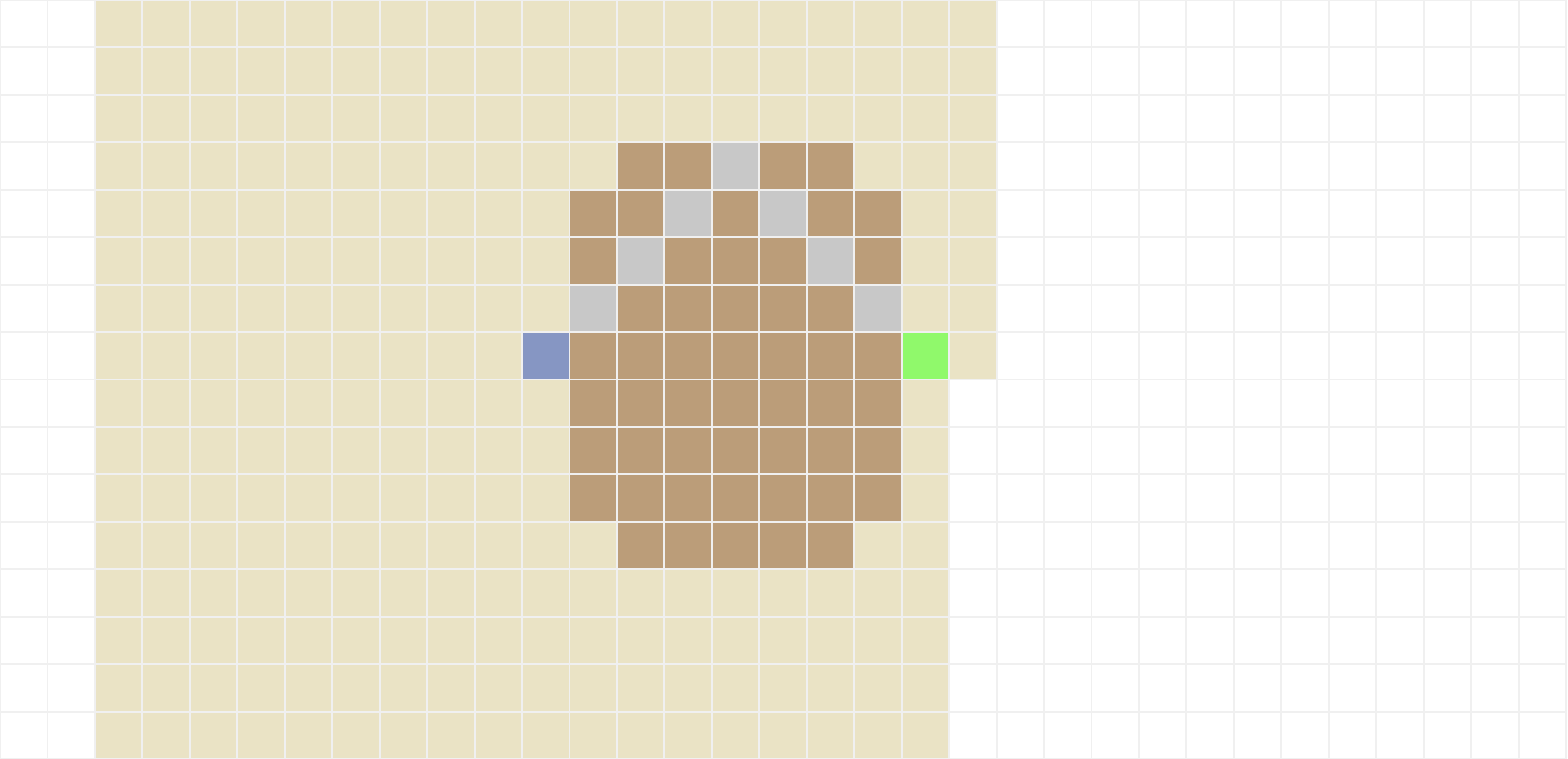
2.2 Busca em profundidade
A implementação da busca em profundidade é muito similar à da busca em largura. A única diferença é que na busca em profundidade, a fronteira é implementada como uma pilha (LIFO), ao invés de uma fila (FIFO). O resultado esperado para os mapas 1, 3 e 7 são os seguintes:


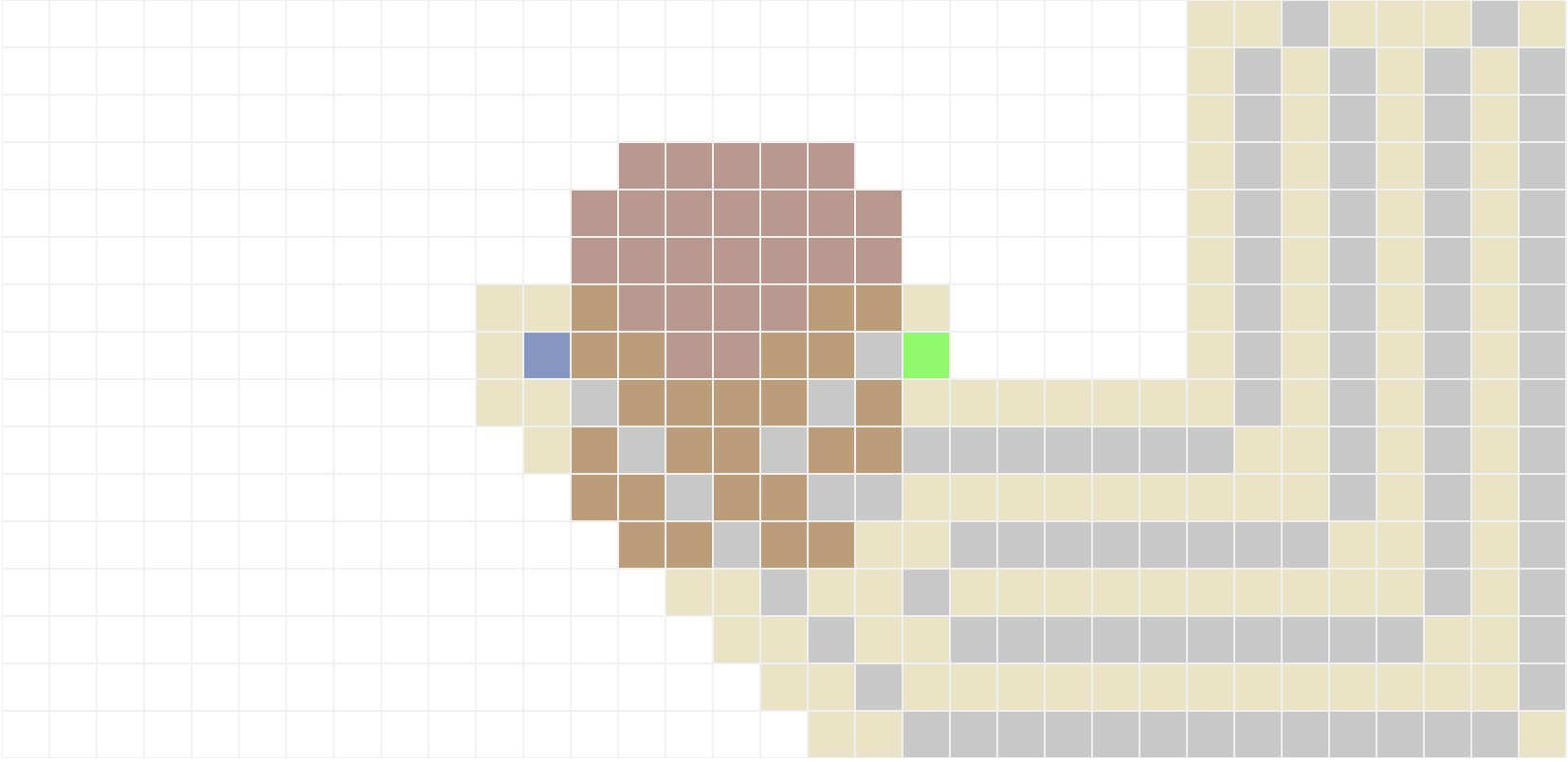
2.3 Busca de custo uniforme
A implementação da busca de custo uniforme também é muito similar à da busca em largura. A diferença é que na busca de custo uniforme, a fronteira é implementada como uma fila de prioridades (heap), onde as prioridades dos nós são dadas pelo custo de seus caminhos até a raiz. O Python possui o módulo heapq que já foi importado para você criar e manipular a fila de prioridade. Além disso, um estado já visitado pode ser adicionado novamente na fronteira caso o custo de seu caminho atual seja menor do que o custo do caminho encontrado até agora. O resultado esperado para os mapas 1, 3 e 7 são os seguintes:

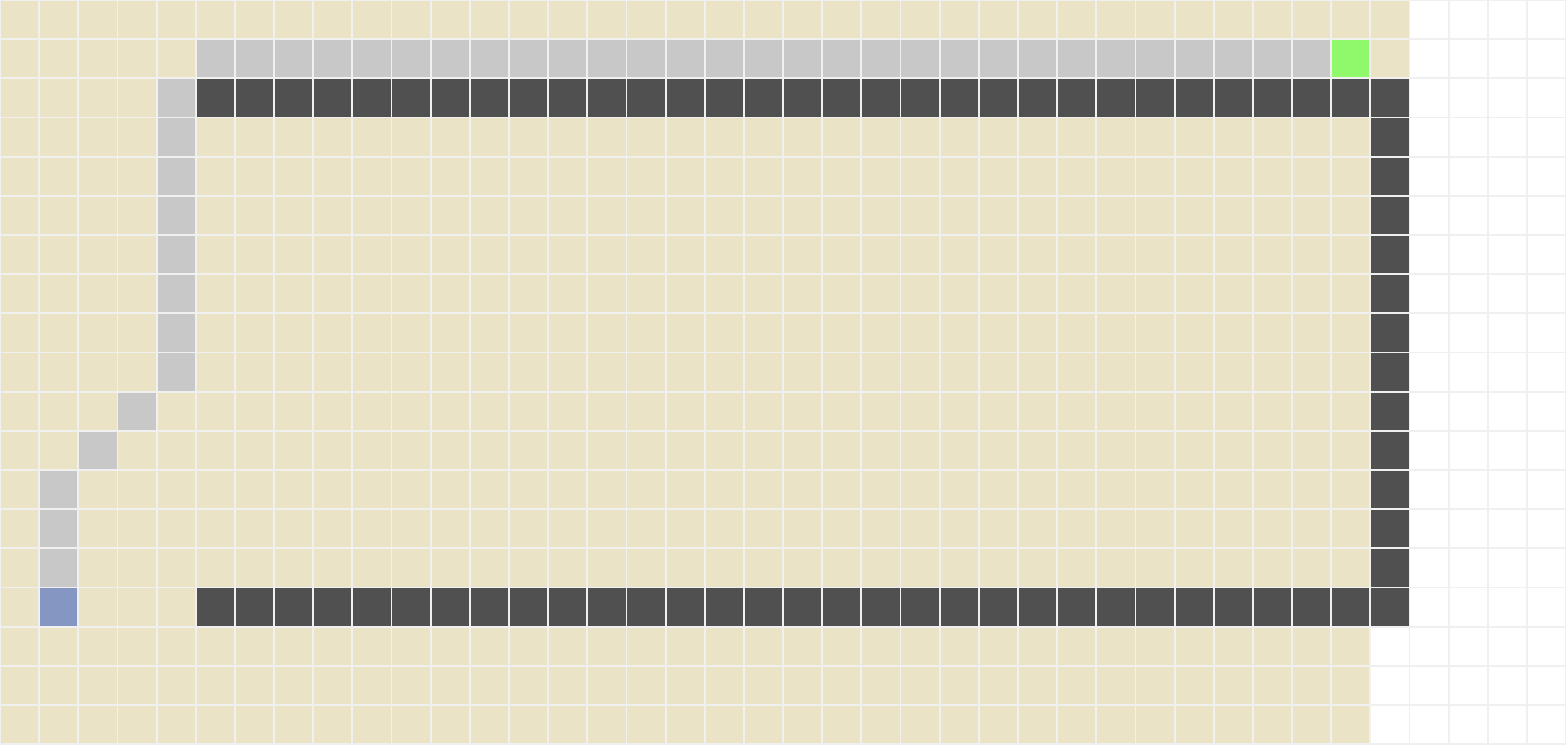
3. Busca informada
Após concluir a implementação dos algoritmos de busca não informada, você pode iniciar a implementação dos algoritmos de busca informada.
3.1 Funções heurísticas
O primeiro passo consiste em implementar as funções heurísticas de distância euclidiana h_euclidean e de distância de Manhattan h_manhattan. Ambas recebem como parâmetros um estado s e um estado final g, e devem retornar a distância entre esses dois estados.
3.2 Busca gulosa por melhor escolha
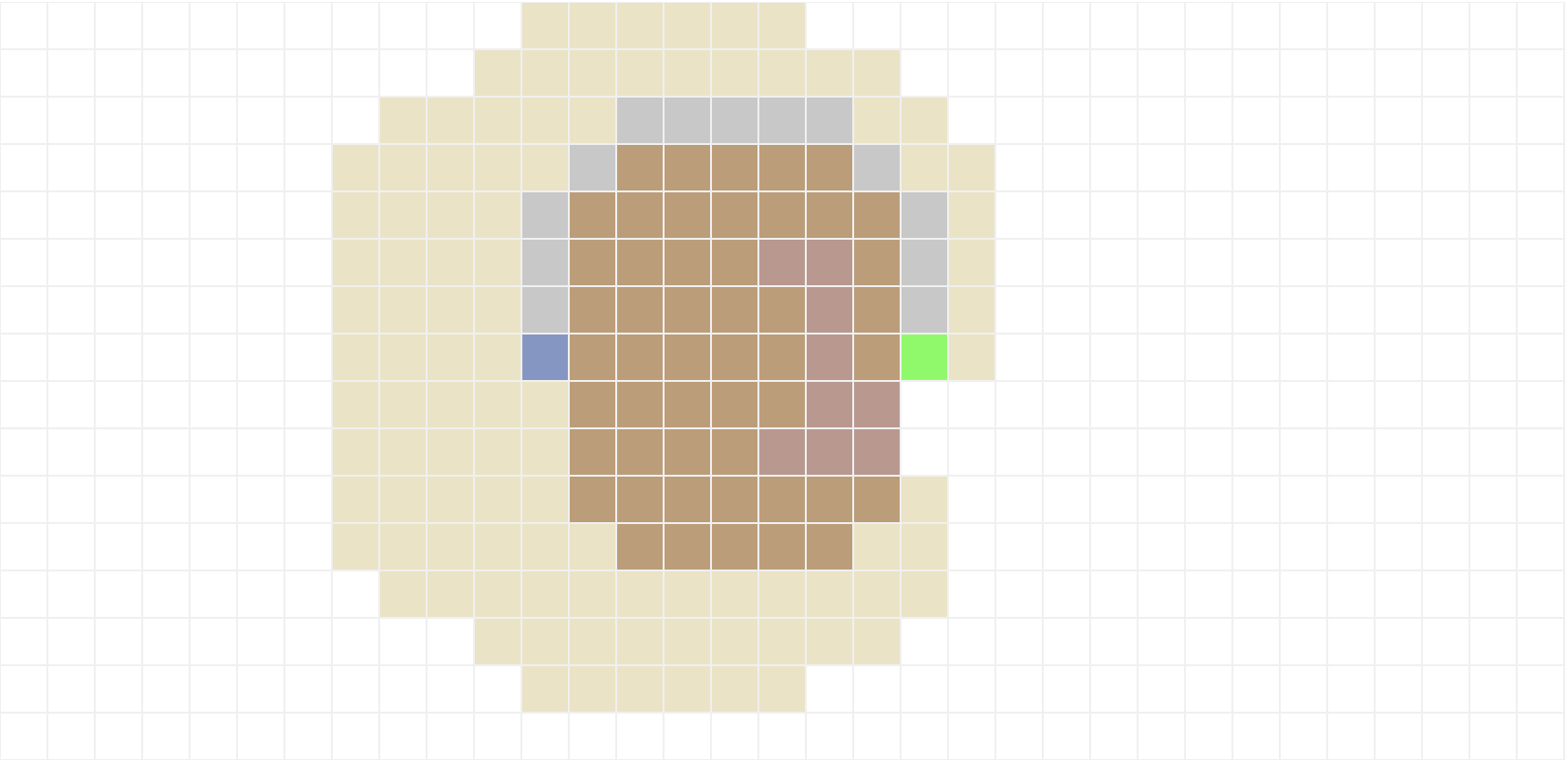
O primeiro algoritmo de busca informada que você irá implementar é a busca gulosa por melhor escolha. Assim como os algoritmos de busca não informada, este também será muito similar à implementação da busca em largura. A diferença é que a fronteira é implementada como uma fila de prioridades (heap), onde a prioridade de um nó s é dada pela função heurística h(s, g). O resultado esperado para os mapas 1, 3 e 7 com a heurística de distância euclidiana são os seguintes:



3.3 Algoritmo A*
O segundo algoritmo é o A*, que combina a busca gulosa por melhor escolha e por custo uniforme. Dessa forma, a fronteira também é implementada como uma fila de prioridades (heap), porém a prioridade de um nó s é dada pela soma g(s) + h(s, g), da função heurística h(s, g) com o custo g(s) do melhor caminho encontrado até agora para s. Além disso, assim como na busca por custo uniforme, um estado já visitado pode ser adicionado novamente na fronteira caso o custo de seu caminho atual seja menor do que o custo do caminho encontrado até agora. O resultado esperado para os mapas 1, 3 e 7 com a heurística de distância euclidiana são os seguintes:

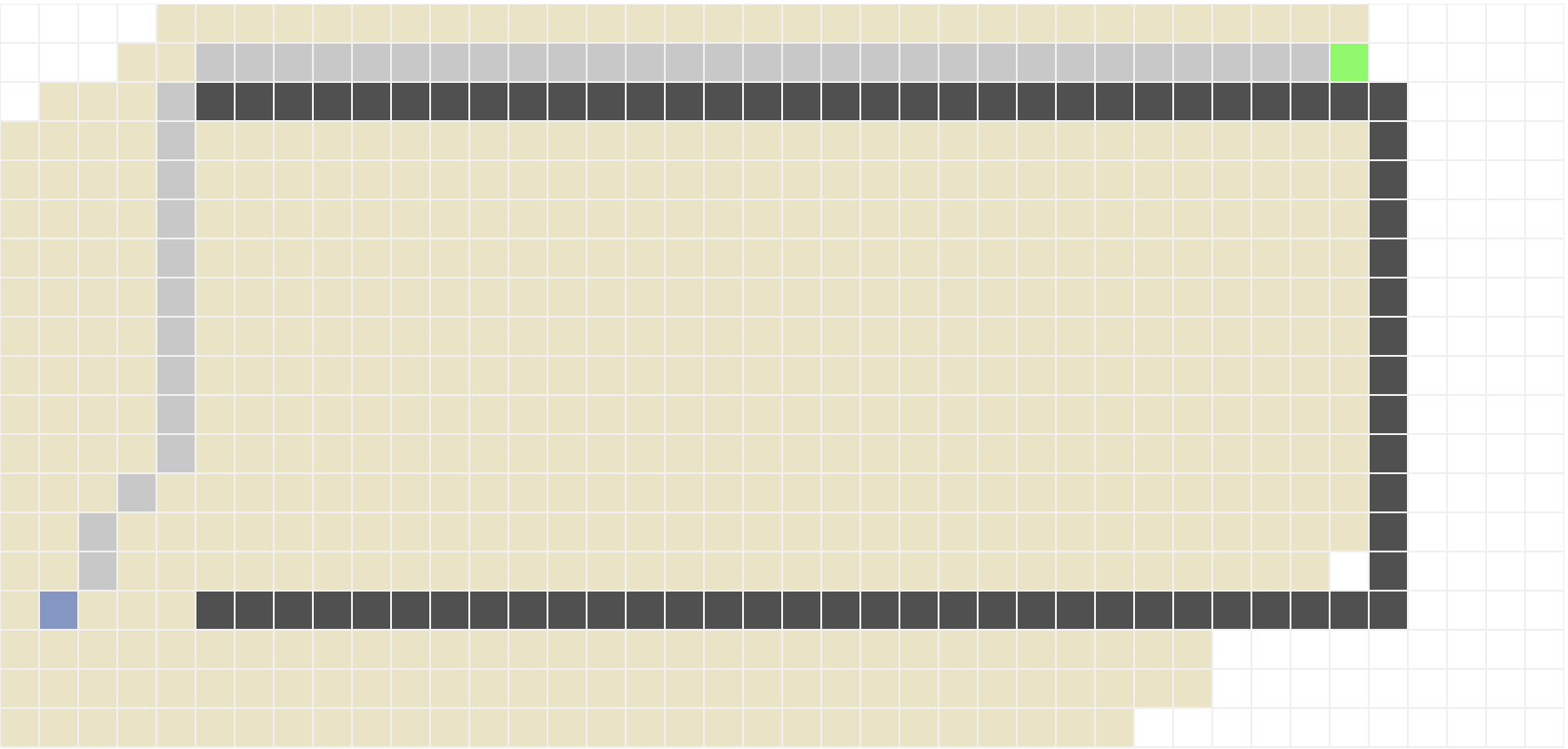
4. Relatório
Após concluir a implementação dos algoritmos de busca, você irá criar casos de teste e reportar os resultados encontrados. Crie pelo menos 7 novos mapas (com tamanhos distintos) para analisar sua implementação, cada um com uma das seguintes características:
- BFS não é ótimo
- BFS é equivalente à UCS
- DFS retorna a solução ótima
- Greedy é ótimo
- Greedy não é ótimo
- A* é melhor que UCS
- A* é equivalente à UCS
Compare o desempenho dos algoritmos em relação ao número de nós visitados, custo e tamanho do caminho retornado (esses valores são impressos no terminal pelo servidor após a execução da busca). Nos mapas de teste dos algoritmos de busca informada, discuta o impacto das diferentes heurísticas no desempenho dos algoritmos. O seu relatório deve conter no máximo 2 páginas no formato da Association for the Advancement of Artificial Intelligence (AAAI) (disponível também no Overleaf).
Submissão
Para submeter o seu trabalho, submeta o seu arquivo search.py e o seu relatório relatorio.pdf (em formato pdf) na tarefa TP1 - Busca no espaço de estados no PVANet.