TP3 - Aprendizado por reforço
Introdução
Nesse projeto você irá implementar o algoritmo de q-learning tabular para criar um agente infeligente que aprende a jogar o Snake. Para isso, você irá utilizar o algoritmo epsilon-greedy para escolher ações durante o aprendizado. O objetivo deste projeto é praticar a modelagem e a implementação de algoritmos de aprendizado por reforço, bem como analisar os resultados desse tipo de algoritmo, em particular o impacto dos parâmetros do algoritmo no desempenho do agente.
Código-base
Executar servidor
Clique aqui para baixar o código-base, que inclui um cliente em JavaScript para configurar os parâmetros do algoritmo, carregar mapas, iniciar a busca e salvar os resultados. Além disso, o código também contém um servidor em Python para implementar e executar o algoritmo de q-learning. Para executar o servidor, você precisará instalar as dependências do projeto e iniciar o servidor com os seguintes comandos:
pip install -r requirements.txt # Instalar dependencias
python3 server.py -port 5001 # Executar o servidor
Assim que o servidor iniciar, você pode abrir o seguinte endereço em qualquer navegador: http://localhost:5001.
Tarefas
Todas as suas tarefas de implementação serão realizadas no arquivo learn.py. Antes de começar sua implementação, abra esse arquivo e se familiarize com as funções definidas nesse arquivo. Em seguida, estude a função q_update() do arquivo serve.py, pois ela que executa as funções que terá que implementar.
1. Representação dos estados
Talvez a forma mais trivial de representar estados no jogo Snake seria armazenar explcitamete as posições de todos os elementos do jogo importantes para o agente, como muros, espaços em branco, cabeça da cobra, comida e calda da cobra. Apesar de completa, essa representação define um espaço de estados muito grande e difícil generalização para o q-learnin tabular. Sendo assim, você irá implementar uma representação mais compacta, que considera as seguintes características:
- Orientação horizontal: a cobra está à esquerda (0), à direita (1), ou na mesma posição da comida (2)?
- Orientação vertical: a cobra está abaixo (0), acima (1), ou na mesma posição da comida (2)?
- Perigos adjacentes: existem (1) ou não (0) uma parede ou pedaços de cauda nos quadrados adjacentes: acima, direita, abaixo, esquerda?
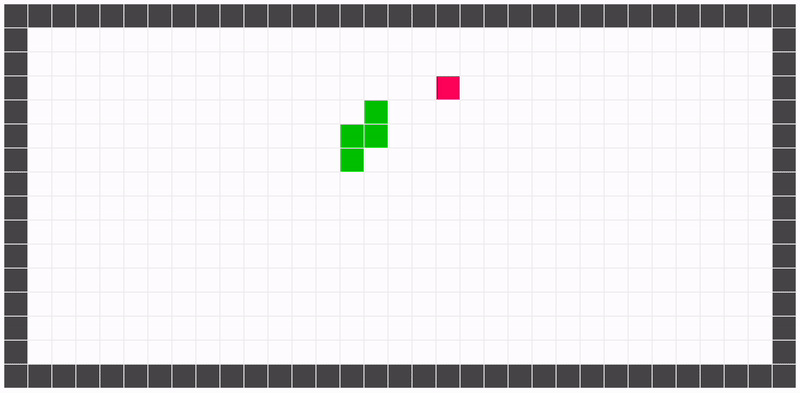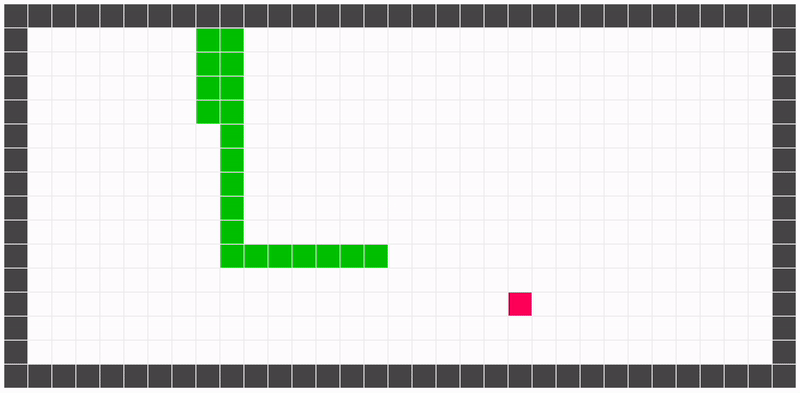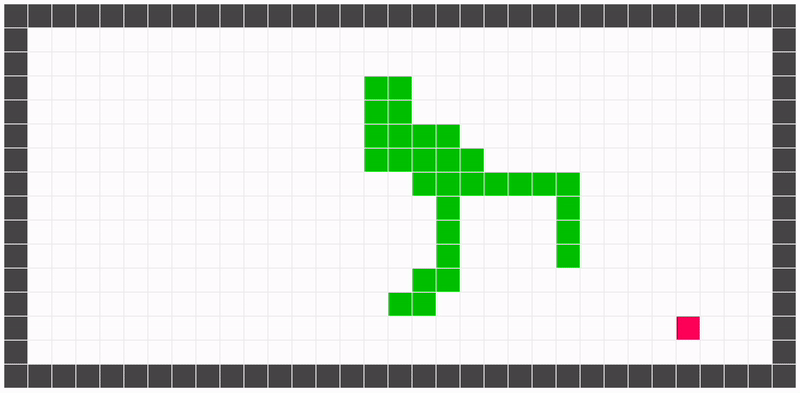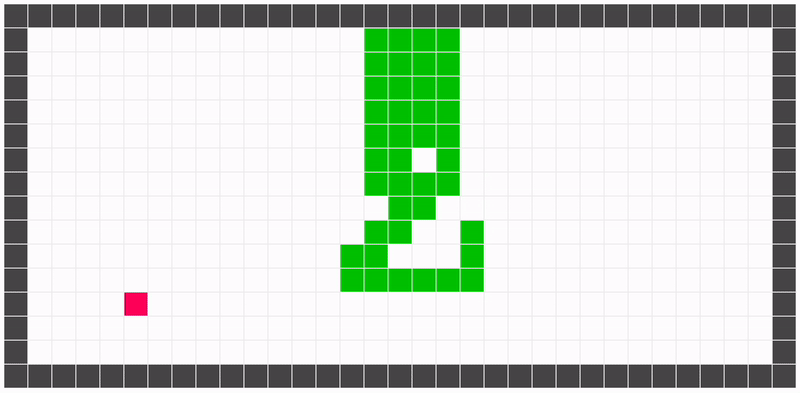
Essa representação nos permite reduzir e generalizar um pouco os estados do jogo. Por exemplo, as duas configuração de jogo ilustradas abaixo são representadas pelo mesmo estado:
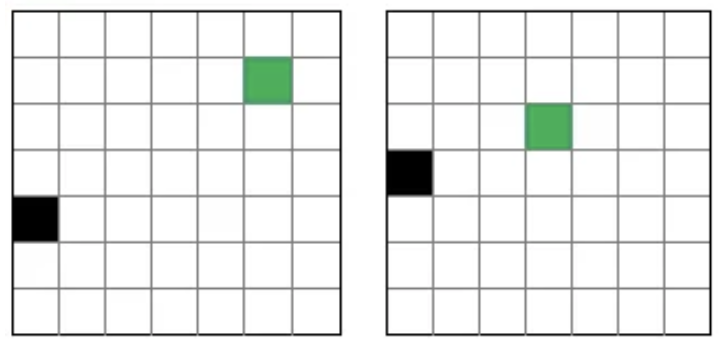
Uma forma de codificar essa representação para o q-learning consiste em utilizar string de 6 caracteres, como a seguinte:
"000000"
Onde os dois primeiros caracteres codificam as orientações horizontal e vertical da cobra relativa à comida, respectivamente, e os caracteres restantes, a existência de pares ou pedaçoes de cauda nos quadrados de cima, direita, baixo e esquerda, respectivamente. No exemplo acima, o primeiro caractere “0” indica que a cobra está à esquerda da comida. O segundo “0” que a cobra está abaixo da comida. Os 4 últimos caracteres (“0000”) indicam que não existem blocos ou pedaços de calda acima nem à direita, mas eles existem abaixo e à esquerda da cobra. É importante destacar que, apesar de parecer, essa string não é um arranjo de bits, pois os dois primeiros elementos podem ter valores 0, 1 e 2.
Sua primeira tarefa é implementar a função get_state(level), que recebe como parâmetro um objeto level, contendo as posições de todos os elementos do jogo: muros, espaços em branco, cabeça da cobra, comida e calda da cobra. Essa função deve retornar uma string de 6 caracteres, codificando os elementos de level utilizando a representação definida acima.
2. Inicializar tabela de valores Q
Sua próxima tarefa é implementar a função init_q_table(), que deve retornar uma dicionário representando a tabela inicial de valores q. Para isso, instancie um dicionário q_table e o inicialize com uma par {state: {'w': 0, 'a': 0, 's': 0, 'd': 0}} para cara estado state possível na representação descrita na seção anterior. O seu dicionário deve ter uma estrutura como a seguir:
{
'000000': {'w': 0, 'a': 0, 's': 0, 'd': 0},
'000001': {'w': 0, 'a': 0, 's': 0, 'd': 0},
'000010': {'w': 0, 'a': 0, 's': 0, 'd': 0},
'000011': {'w': 0, 'a': 0, 's': 0, 'd': 0},
...
'221111': 0{'w': 0, 'a': 0, 's': 0, 'd': 0}
}
Note que o valor de cada entrada no dicionário é também um dicionário, mas com 4 chaves, uma para cada ação possível: ‘w’, ‘a’, ‘s’ e ‘d’. Essas ações representam o movimento para cima, esquerda, baixo e direita, respectivamente. A variável global ACTIONS = ['w', 's', 'd', 'a'] definida no início do arquivo foi criada para facilitar a referência às ações válidas no jogo..
3. Atualizar valores de Q
A teceira tarefa é implementar a regra de atualização do q-learning na função update_q_table(s, a, r, s_prime, q_table, alpha, gamma). Lembre-se que a o q-larning atualize uma única entrada na tabela a cada experiência do agente, seguindo a seguinte regra:
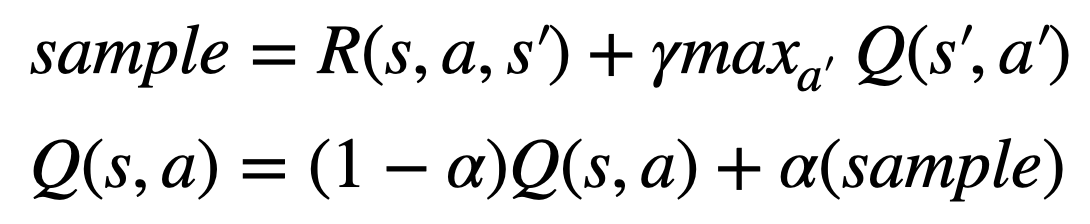
Sua implementação deve atualizar apenas um dos valores da tabela q_table passada como parâmetro, sgundo a regra acima. Você não precisa retornar a tabela q_table como resultado dessa função!.
4. Escolher uma ação com e-greedy
A quarta tarefa é implementar o algoritmo e-greedy para selecionar uma ação para o agente executar a cada iteração do algoritmo. Você deve implementar o e-greedy na função choose_action(state, q_table, epsilon). Lembre-se que o e-greedy decide explorar uma ação aleatória com probabilidade epsilon:
- Antes de executar uma ação, gere um valor
pentre 0 e 1 - Se
p < epsilon, escolha uma ação aleatória - Caso contrário, escolha a ação com maior
q_table(s,a)
Sua implementação deve retornar uma ação válida do jogo: w, a, s, d.
5. Função de recompensa
Sua última tarefa é implementar a função de recompensas reward_function(level, level_prime), que recebe as configurações anterior level e atual do mapa level_prime. Utilize essas estruturas parar retornar os seguintes valores de recompensa:
+100se a cabeça da cobra estiver na mesma posição da comida no mapa atual;-100se a cabeça da cobra estiver na mesma posição de um muro ou de um pedaço de calda;1se a distância horizontal ou vertical entre a cabeça da cobra e a comida for menor no mapa;atual do que mapa anterior-1caso contrário.
6. Experimentos
Após concluir a implementação do seu agente, você irá analisar o seu desempenho no mapa mapa1_aberto com relação ao valores de epsilon. Quando você clicar no botão Iniciar, o cliente javascript já irá executar uma série de experimentos para você. Ele está configurado para jogar 30 partidas após as os seguintes números de episódios: [16, 32, 64, 128, 256, 512, 1024, 2048, 4096, 8192]. Ao final de cada série de 30 partidas, os resultados das mesmas são enviados automaticamente ao servidor e armazenados em um arquivo /results/experiment_results.csv. Você também pode clicar no botão Salvar se quiser salvar esses resultados durante qualquer momento do treinamento.
Para analisar o desempenho do seu agente, deixe ele executar até o final dos 8192 episódios para cada uma das configurações de parâmetros a seguir:
Epsilon (Max): 1,Epsilon (Min): 0.001,Lambda: 0.001(configuração inicial)Epsilon (Max): 0.8,Epsilon (Min): 0.001,Lambda: 0(sem epsilon decay)Epsilon (Max): 0.5,Epsilon (Min): 0.001,Lambda: 0(sem epsilon decay)
Ao final de cada experimento, renomeie o arquivo /results/experiment_results.csv para que ele não seja sobrescrito. Após a execução dos 3 experimentos, escreva um script em python para plotar os 3 gráficos de pontuação média do agente ao longo dos 8192 episódios, como na figura a seguir:
7. Customização nos estados
Agora que você concluiu a implementação do seu agente, implemente em uma representação alternativa de estados e execute 1 único experimento (até os 8192 episódios) com a configuração de parâmetros que desejar. Salve os resultados e plote o gráfico de desempenho médio como na seção anterior.
8. Relatório
Escreva um relatório introduzindo brevemente os detalhes do seu agente e discutindo o impacto das diferentes configurações de epsilon no seu desempenho. Inclua também os resultados da customização que você implementou na Seção 7.
Seu relatório deve conter no máximo 2 páginas no formato da Association for the Advancement of Artificial Intelligence (AAAI) (disponível também no Overleaf).
Submissão
Para submeter o seu trabalho, envie o seu arquivo learn.py e o seu relatório relatorio.pdf (em formato pdf) na tarefa TP3 - Aprendizado por reforço no PVANet.